Discrete Fourier Transform
Discrete Fourier Transform (DFT) is an important technique in the science of speech and sound measurement. It provides the frequency information of the signal. This post will be devoted to introduce the use of DFT in data science.
Audio Signal Processing
An audio signal can be represented as an encoding of air pressure over time. Formally, it is a function \(S\colon \mathbb{R} \to \mathbb{R}\) that maps every every point \(t\) in time to sound pressure value \(S_t = S(t)\). The representation of how air pressure moves over time is called analog or continuous time signal. In order to process and store audio signals digitally on computers or electronic devices, it often involves discretizing signals, referred to as sampling. The sound wave is converted into data through a series of snapshot measurements, or samples. A sample is taken at a particular time in the audio wave, recording amplitude. This information is then converted into binary data.
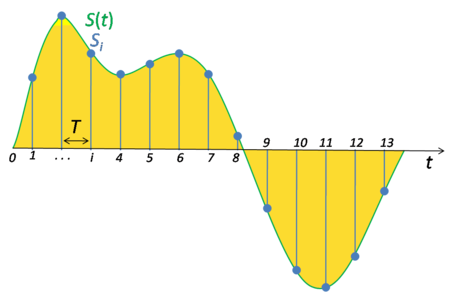
Fig. 1. Signal sampling representation. (Image source: Wikipedia)
{kind=link}
The quality of sound depends on the following two factors
- Sampling rate (also called sampling frequency) is the number of samples per second measured in Hertz (Hz). The most common sample rate is 44.1 kHz, or 44,100 samples per second for audio. Human can hear between 20 Hz and 20 kHz.
- Bit depth determines the number of possible values that we can record for each sample. The most common bit depths are 16-bit, 24-bit, and 32-bit. Bit depth affects the quantization, which is a process of discretize real amplitude values using a finite set of integers.
Sampling, in general, is not invertible function and results in loss of information (i.e., aliasing). The higher the sampling rate, the more accurate would be to stored information and the construction from its samples. Which is the minimum necessary sampling frequency for a given type of signal that allows accurate reconstruction? The answer is given by Nyquist-Shannon Sampling Theorem [1].
The sampling frequency should be at least twice the highest frequency contained in the signal.
Here, the frequency is defined as the number of cycles that the signal completes in one second. This value is measured in Hertz (Hz). Nyquist rate refers to the number of sampling rate for a frequency to not alias, whereas Nyquist frequency refers to the maximum frequency that will not alias given a sampling rate.
To understand sound signals, a common step is to decompose it into fundamental components, known as frequencies (see Fig. 2). In the next section, we will discuss the motivation of using Discrete Fourier Transform (DFT) for frequency representation.
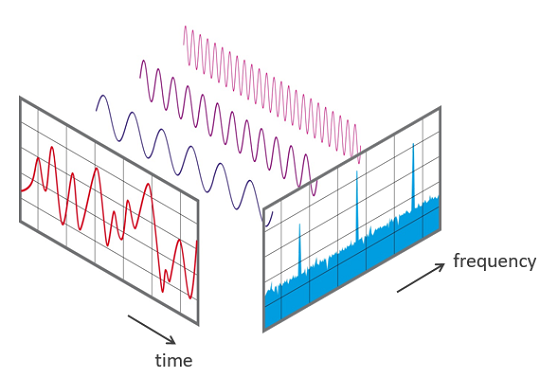
Fig. 2. How signal is viewed in the domain of time and frequency (Image source: Nti-audio)
Fourier Series
Any periodic function can be written as a Fourier series.
A Fourier series provides a way to expand a periodic function by a series in terms of sine and cosine functions.
Discrete Fourier Transform
Any function can be decomposed into frequency components.
Given any time series \(x_0, x_1, \dots, x_{K-1}\), it can be expressed as follows
\[x_i = \sum_{k=0}^{K-1} \hat{x}_k \exp(-2\pi ki/K)\,,\]where
\[\hat{x}_i = \frac{1}{K}\sum_{k=0}^{K-1} x_k \exp(2\pi ki/K)\,.\]Applications of DFT
References
[1] Nyquist, Harry. “Certain factors affecting telegraph speed.” Transactions of the American Institute of Electrical Engineers 43 (1924): 412-422.